 I got the following question recently.
I got the following question recently.
What is the difference between Dispose and SupressFinalize in garbage collection?”
The problem with this question is it assumes Dispose and SupressFinalize have similarities, which I’m sure is not what is being asked here. So let’s rephrase it in terms that make sense.
I see three methods available to me in .NET that all seem to have something to do with garbage collection. Can you explain what Dispose, Finalize, and SupressFinalize do and why I could use or call each one in my code?”
 By now, most people are familiar with the fact that ASP.NET will send mail from the codebehind by simply adding a few lines to your web.config file and adding another few lines of code in the codebehind file.
By now, most people are familiar with the fact that ASP.NET will send mail from the codebehind by simply adding a few lines to your web.config file and adding another few lines of code in the codebehind file.
 In previous posts, I’ve covered the core architecture of jQuery. How it works. How you call methods. A brief overview of what’s available.
In previous posts, I’ve covered the core architecture of jQuery. How it works. How you call methods. A brief overview of what’s available.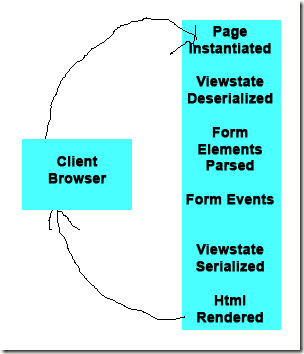 I received the following question recently about my article “
I received the following question recently about my article “ When you need to deal with a number that is a fraction, what do you specify for its type? If you are like most programmers I know, you’ll reach for Float (Single if you are using VB) or Double.
When you need to deal with a number that is a fraction, what do you specify for its type? If you are like most programmers I know, you’ll reach for Float (Single if you are using VB) or Double. It seems like such a trivial thing to be talking about but not knowing the difference between && vs & or || vs | can make a huge difference between working code and code that only seems to work. Let me illustrate:
It seems like such a trivial thing to be talking about but not knowing the difference between && vs & or || vs | can make a huge difference between working code and code that only seems to work. Let me illustrate: Over the weekend I got a question about how to prevent postbacks on buttons from within jQuery tabs. But the question really isn’t specific to jQuery. There are other times when you might not want a button to post back. So how do you do this? There are several ways you might accomplish this depending on what your goal is. The first, and most obvious choice, is to not use an ASP:Button control and use an HTML input type=”button” tag instead. This will allow you to have full control over what is happening on the client side. If at all possible, this should be your first choice.
Over the weekend I got a question about how to prevent postbacks on buttons from within jQuery tabs. But the question really isn’t specific to jQuery. There are other times when you might not want a button to post back. So how do you do this? There are several ways you might accomplish this depending on what your goal is. The first, and most obvious choice, is to not use an ASP:Button control and use an HTML input type=”button” tag instead. This will allow you to have full control over what is happening on the client side. If at all possible, this should be your first choice. Jeff Atwood of
Jeff Atwood of 